tips:
成员方法不外乎是“增删改查”,这也反映了我们编写程序时,一定是以“数据”为导向的。
映射表(map)数据结构的设计由来
集是一个集合,它可以快速地查找现有的元素。但是,要查看一个元素,需要有要查找元素的精确副本。这不是一种非常通用的查找方式。
通常,我们知道某些键的信息,并想要查找与之对应的元素。映射表(map)数据结构就是为此设计的。映射表用来存放键/值对。如果提供了键,就能够查找到值。例如,有一张关于员工信息的记录表,键为员工ID,值为Employee对象。
Java类库为映射表提供了两个通用的实现:HashMap 和 TreeMap。这两个类都实现了Map接口。
散列映射表(HashMap)对键进行散列,树映射表(TreeMap)用键的整体顺序对元素进行排序,并将其组织成搜索树。散列或比较函数只能作用于键。与键关联的值不能进行散列或比较。
另外提一下AbstractMap抽象类。 AbstractMap 对Map中的方法提供了一个基本实现,减少了直接去实现Map接口的工作量。
Map的方法和内部类
在eclipse中的outline面板可以看到 Map 接口里面包含以下成员方法与内部类:
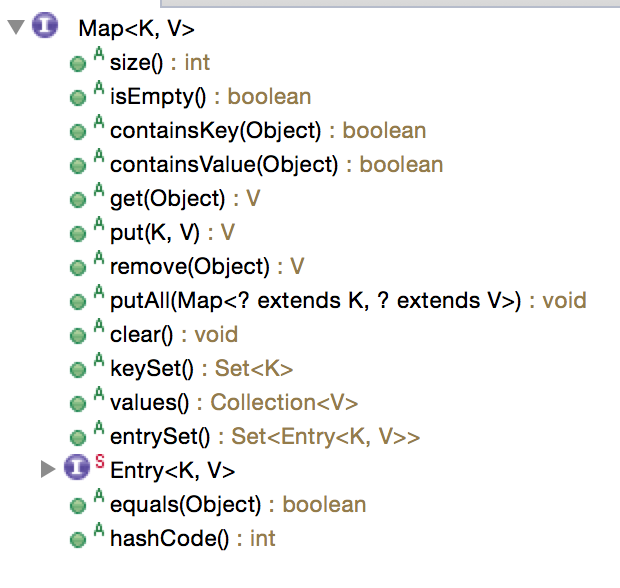
可以看到,这里的成员方法不外乎是“增删改查”,这也反映了我们编写程序时,一定是以“数据”为导向的。
了解Map接口和方法
Java核心类中有很多预定义的Map类。在介绍具体实现之前,先介绍一下Map接口本身,一遍了解所有实现的共同点。(因为接口是一个规范。)Map接口定义了四种类型的方法,每个Map的具体实现都包含这些方法。
覆盖的方法
我们将这Object的这两个方法覆盖,以正确比较Map对象的等价性。
- boolean equals(Object o) 比较指定的对象与此映射是否相等。
- int hashCode() 返回此映射的哈希码值
Map构建的方法
Map定义了几个用于插入和删除元素的变换方法,可以更改Map内容。
- void clear() 从此映射中移除所有映射关系(可选操作)
- V remove(Object key)如果存在一个键的映射关系,则将其从此映射中移除(可选操作)
- V put(K key, V value)将指定的值与此映射中的指定键关联(可选操作)
- void putAll(Map<? extend K, ? extends V> m) 从指定映射中将所有映射关系复制到此映射中(可选操作)
查看Map的方法
迭代 Map 中的元素不存在直接了当的方法。如果要查询某个 Map 以了解其哪些元素满足特定查询,或如果要迭代其所有元素(无论原因如何),则您首先需要获取该 Map 的“视图”。映射表(Map)有三种可能的视图,这是一组实现了 Collection 接口对象,或者它的子接口的视图。
有3个视图,分别是:键集,值集合(不是集?? 集合与集的关系?),键/值对集。返回视图的Map方法:使用这些方法返回的对象,您可以遍历Map的元素,还可以删除Map中的元素。
- Set
keySet() 返回此映射中包含的键的Set视图。删除Set中的元素还将删除Map中相应的映射(键和值) - Collection
values() 返回此映射中包含的值的Collection视图。删除Collection中的元素还将删除Map中相应的映射(键和值) - Set
访问元素的方法
Map通常适合按键(而非按值)进行访问。Map 定义中没有规定这肯定是真的,但通常您可以期望这是真的。例如,您可以期望 containsKey() 方法与 get() 方法一样快。另一方面,containsValue() 方法很可能需要扫描 Map 中的值,因此它的速度可能比较慢。
Map访问和测试方法:这些方法检索有关Map内容的信息但不更改Map内容。
- V get(Object key) 返回指定键所映射的值;如果此映射不包含改键的映射关系,则返回null。
- boolean containsKey(Object key) 如果此映射包含指定键的映射关系,则返回true。
- boolean containsValue(Object value) 如果此映射将一个或多个键映射到指定值,则返回true。
- boolean isEmpty() 如果此映射未包含键-值映射关系,则返回true。
- int size() 返回此映射中的键-值映射关系数。
核心Map
Java自带了各种Map类。这些 Map 类可归为三种类型:
通用 Map,用于在应用程序中管理映射,通常在 java.util 程序包中实现
- HashMap
- Hashtable
- Properties
- LinkedHashMap
- IdentityHashMap
- TreeMap
- WeakHashMap
- ConcurrentHashMap
专用 Map,您通常不必亲自创建此类 Map,而是通过某些其他类对其进行访问
java.util.jar.Attributes
- javax.print.attribute.standard.PrinterStateReasons
- java.security.Provider
- java.awt.RenderingHints
- javax.swing.UIDefaults
一个用于帮助实现您自己的 Map 类的抽象类
- AbstractMap
内部哈希:哈希映射技术
几乎所有通用 Map 都使用哈希映射。这是一种将元素映射到数组的非常简单的机制,您应了解哈希映射的工作原理,以便充分利用 Map。
哈希映射结构由一个存储元素的内部数组组成。由于内部采用数组存储,因此必然存在一个用于确定任意键访问数组的索引机制。实际上,该机制需要提供一个小于数组大小的整数索引值。该机制称作哈希函数。在 Java 基于哈希的 Map 中,哈希函数将对象转换为一个适合内部数组的整数。您不必为寻找一个易于使用的哈希函数而大伤脑筋: 每个对象都包含一个返回整数值的 hashCode() 方法。要将该值映射到数组,只需将其转换为一个正值,然后在将该值除以数组大小后取余数即可。以下是一个简单的、适用于任何对象的 Java 哈希函数
int hashvalue = Maths.abs(key.hashCode()) % table.length;
(% 二进制运算符(称作模)将左侧的值除以右侧的值,然后返回整数形式的余数。)
实际上,在 1.4 版发布之前,这就是各种基于哈希的 Map 类所使用的哈希函数。但如果您查看一下代码,您将看到
int hashvalue = (key.hashCode() & 0x7FFFFFFF) % table.length;
它实际上是使用更快机制获取正值的同一函数。在 1.4 版中,HashMap 类实现使用一个不同且更复杂的哈希函数,该函数基于 Doug Lea 的 util.concurrent 程序包(稍后我将更详细地再次介绍 Doug Lea 的类)。
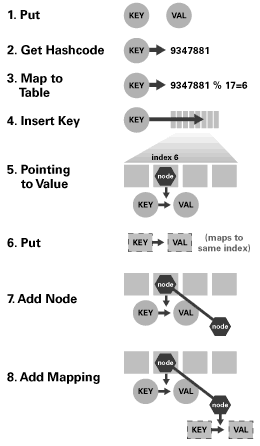
该哈希工作原理图介绍了哈希映射的基本原理,但我们还没有对其进行详细介绍。我们的哈希函数将任意对象映射到一个数组位置,但如果两个不同的键映射到相同的位置,情况将会如何? 这是一种必然发生的情况。在哈希映射的术语中,这称作冲突。Map 处理这些冲突的方法是在索引位置处插入一个链接列表,并简单地将元素添加到此链接列表。因此,一个基于哈希的 Map 的基本 put() 方法可能如下所示
|
|
如果看一下各种基于哈希的 Map 的源代码,您将发现这基本上就是它们的工作原理。此外,还有一些需要进一步考虑的事项,如处理空键和值以及调整内部数组。此处定义的 put() 方法还包含相应 get() 的算法,这是因为插入包括搜索映射索引处的项以查明该键是否已经存在。(即 get() 方法与 put() 方法具有相同的算法,但 get() 不包含插入和覆盖代码。) 使用链接列表并不是解决冲突的唯一方法,某些哈希映射使用另一种“开放式寻址”方案,本文对其不予介绍。
优化 Hasmap
如果哈希映射的内部数组只包含一个元素,则所有项将映射到此数组位置,从而构成一个较长的链接列表。由于我们的更新和访问使用了对链接列表的线性搜索,而这要比 Map 中的每个数组索引只包含一个对象的情形要慢得多,因此这样做的效率很低。访问或更新链接列表的时间与列表的大小线性相关,而使用哈希函数问或更新数组中的单个元素则与数组大小无关 — 就渐进性质(Big-O 表示法)而言,前者为 O(n),而后者为 O(1)。因此,使用一个较大的数组而不是让太多的项聚集在太少的数组位置中是有意义的。
调整 Map 实现的大小
在哈希术语中,内部数组中的每个位置称作“存储桶”(bucket),而可用的存储桶数(即内部数组的大小)称作容量 (capacity)。为使 Map 对象有效地处理任意数目的项,Map 实现可以调整自身的大小。但调整大小的开销很大。调整大小需要将所有元素重新插入到新数组中,这是因为不同的数组大小意味着对象现在映射到不同的索引值。先前冲突的键可能不再冲突,而先前不冲突的其他键现在可能冲突。这显然表明,如果将 Map 调整得足够大,则可以减少甚至不再需要重新调整大小,这很有可能显著提高速度。
使用负载因子
为确定何时调整大小,而不是对每个存储桶中的链接列表的深度进行记数,基于哈希的 Map 使用一个额外参数并粗略计算存储桶的密度。Map 在调整大小之前,使用名为“负载因子”的参数指示 Map 将承担的“负载”量,即它的负载程度。负载因子、项数(Map 大小)与容量之间的关系简单明了:
- 如果(负载因子)x(容量)>(Map 大小),则调整 Map 大小
例如,如果默认负载因子为 0.75,默认容量为 11,则 11 x 0.75 = 8.25,该值向下取整为 8 个元素。因此,如果将第 8 个项添加到此 Map,则该 Map 将自身的大小调整为一个更大的值。相反,要计算避免调整大小所需的初始容量,用将要添加的项数除以负载因子,并向上取整,例如,
- 对于负载因子为 0.75 的 100 个项,应将容量设置为 100/0.75 = 133.33,并将结果向上取整为 134(或取整为 135 以使用奇数)
奇数个存储桶使 map 能够通过减少冲突数来提高执行效率。虽然我所做的测试(关联文件中的 并未表明质数可以始终获得更好的效率,但理想情形是容量取质数。1.4 版后的某些 Map(如 HashMap 和 LinkedHashMap,而非 Hashtable 或 IdentityHashMap)使用需要 2 的幂容量的哈希函数,但下一个最高 2 的幂容量由这些 Map 计算,因此您不必亲自计算。
负载因子本身是空间和时间之间的调整折衷。较小的负载因子将占用更多的空间,但将降低冲突的可能性,从而将加快访问和更新的速度。使用大于 0.75 的负载因子可能是不明智的,而使用大于 1.0 的负载因子肯定是不明知的,这是因为这必定会引发一次冲突。使用小于 0.50 的负载因子好处并不大,但只要您有效地调整 Map 的大小,应不会对小负载因子造成性能开销,而只会造成内存开销。但较小的负载因子将意味着如果您未预先调整 Map 的大小,则导致更频繁的调整大小,从而降低性能,因此在调整负载因子时一定要注意这个问题。
选择适当的 Map
应使用哪种 Map? 它是否需要同步? 要获得应用程序的最佳性能,这可能是所面临的两个最重要的问题。当使用通用 Map 时,调整 Map 大小和选择负载因子涵盖了 Map 调整选项。
以下是一个用于获得最佳 Map 性能的简单方法
将您的所有 Map 变量声明为 Map,而不是任何具体实现,即不要声明为 HashMap 或 Hashtable,或任何其他 Map 类实现。
Map criticalMap = new HashMap(); //好
HashMap criticalMap = new HashMap(); //差
这使您能够只更改一行代码即可非常轻松地替换任何特定的 Map 实例。
下载 Doug Lea 的 util.concurrent 程序包 (http://gee.cs.oswego.edu/dl/classes/EDU/oswego/cs/dl/util/concurrent/intro.html)。将 ConcurrentHashMap 用作默认 Map。当移植到 1.5 版时,将 java.util.concurrent.ConcurrentHashMap 用作您的默认 Map。不要将 ConcurrentHashMap 包装在同步的包装器中,即使它将用于多个线程。使用默认大小和负载因子。
监测您的应用程序。如果发现某个 Map 造成瓶颈,则分析造成瓶颈的原因,并部分或全部更改该 Map 的以下内容:Map 类;Map 大小;负载因子;关键对象 equals() 方法实现。专用的 Map 的基本上都需要特殊用途的定制 Map 实现,否则通用 Map 将实现您所需的性能目标。
Map选择
也许您曾期望更复杂的考量,而这实际上是否显得太容易? 好的,让我们慢慢来。首先,您应使用哪种 Map?答案很简单: 不要为您的设计选择任何特定的 Map,除非实际的设计需要指定一个特殊类型的 Map。设计时通常不需要选择具体的 Map 实现。您可能知道自己需要一个 Map,但不知道使用哪种。而这恰恰就是使用 Map 接口的意义所在。直到需要时再选择 Map 实现 — 如果随处使用“Map”声明的变量,则更改应用程序中任何特殊 Map 的 Map 实现只需要更改一行,这是一种开销很少的调整选择。是否要使用默认的 Map 实现? 我很快将谈到这个问题。
同步Map
同步与否有何差别? (对于同步,您既可以使用同步的 Map,也可以使用 Collections.synchronizedMap() 将未同步的 Map 转换为同步的 Map。后者使用“同步的包装器”)这是一个异常复杂的选择,完全取决于您如何根据多线程并发访问和更新使用 Map,同时还需要进行维护方面的考虑。例如,如果您开始时未并发更新特定 Map,但它后来更改为并发更新,情况将如何? 在这种情况下,很容易在开始时使用一个未同步的 Map,并在后来向应用程序中添加并发更新线程时忘记将此未同步的 Map 更改为同步的 Map。这将使您的应用程序容易崩溃(一种要确定和跟踪的最糟糕的错误)。但如果默认为同步,则将因随之而来的可怕性能而序列化执行多线程应用程序。看起来,我们需要某种决策树来帮助我们正确选择。
Doug Lea 是纽约州立大学奥斯威戈分校计算机科学系的教授。他创建了一组公共领域的程序包(统称 util.concurrent),该程序包包含许多可以简化高性能并行编程的实用程序类。这些类中包含两个 Map,即 ConcurrentReaderHashMap 和 ConcurrentHashMap。这些 Map 实现是线程安全的,并且不需要对并发访问或更新进行同步,同时还适用于大多数需要 Map 的情况。它们还远比同步的 Map(如 Hashtable)或使用同步的包装器更具伸缩性,并且与 HashMap 相比,它们对性能的破坏很小。util.concurrent 程序包构成了 JSR166 的基础;JSR166 已经开发了一个包含在 Java 1.5 版中的并发实用程序,而 Java 1.5 版将把这些 Map 包含在一个新的 java.util.concurrent 程序包中。
所有这一切意味着您不需要一个决策树来决定是使用同步的 Map 还是使用非同步的 Map, 而只需使用 ConcurrentHashMap。当然,在某些情况下,使用 ConcurrentHashMap 并不合适。但这些情况很少见,并且应具体情况具体处理。这就是监测的用途。
结束语
通过 Oracle JDeveloper 可以非常轻松地创建一个用于比较各种 Map 性能的测试类。更重要的是,集成良好的监测器可以在开发过程中快速、轻松地识别性能瓶颈 - 集成到 IDE 中的监测器通常被较频繁地使用,以便帮助构建一个成功的工程。现在,您已经拥有了一个监测器并了解了有关通用 Map 及其性能的基础知识,可以开始运行您自己的测试,以查明您的应用程序是否因 Map 而存在瓶颈以及在何处需要更改所使用的 Map。
以上内容介绍了通用 Map 及其性能的基础知识。当然,有关特定 Map 实现以及如何根据不同的需求使用它们还存在更多复杂和值得关注的事项,这些将在本文第 2 部分中介绍。
本文大部分内容来自:Java Map 集合类简介 http://www.oracle.com/technetwork/cn/articles/maps1-100947-zhs.html
小部分来自:《Java核心技术 卷1》